


Understanding the diffusion process
In this blog post, I will attempt to explain the key ideas of the paper "Denoising Diffusion Probabilistic Models" by Ho et al., which introduced the concept of diffusion models for image generation, paving the way for the development of text-to-image models such as DALL-E and Stable Diffusion. These models usually perform much better than GANs and are more stable to train, making them the de-factor industry standard for generative modelling. The actual paper is quite dense and technical, so I will try to simplify the key ideas and concepts in a more general way.
In brief, diffusion models train a neural network to predict the amount of noise that should be removed from a synthetically-noised image to recover the original image. By doing so over multiple images and noise levels, the hypothesis is that the network learns the latent space of the training data. This is a very high-level overview, and I will go into more detail in the following sections.
If you're looking for a more technical explanation, I highly recommend Lilian Weng's amazing blog post covering the whole field in great detail.
An overview of the training process

When training a diffusion model, the high-level steps are:
- Run an image through a forward diffusion process to add noise to it.
- Run the noisy image back through a neural network to predict the amount of noise that should be removed.
- Calculate the loss between the predicted noise and the actual noise
- Update the neural network parameters to minimize the loss using backpropagation.
- Repeat, repeat, repeat.
Let's now go through each of these steps in more detail.
Forward diffusion process (or adding noise)
Given an image (say ), the forward diffusion process adds a small amount of Gaussian noise at each timestep to create a sequence of progressively noisy images (), as shown in the figure below:

Although the idea is to add noise progressively, a few mathematical tricks (namely, reparametrization) allow us to sample the noisy image at any arbitrary timestep without having to compute the intermediate images . The amount of noise is controlled by a noise scheduler, which is typically parameterized by .
Noise schedulers
The amount of noise that is added at each timestep is controlled by a noise scheduler, which is a function that maps the timestep to a particular variance level, thereby controlling the amount of noise added. The two most common noise schedules are the linear schedule (Ho et al. (2020)) and the cosine schedule (Nichol & Dhariwal (2021)). The difference between the two can be seen in the figure below:

As you can see, the linear schedule adds noise linearly, which usually leads to extremely noisy images towards the middle of the diffusion process, while the cosine schedule adds noise in a more controlled manner.
Backward diffusion process (or removing noise)
At this point, we have a noisy image () on our hands, and the amount of noise that was added to it (). It would be great if we could reverse the above noising process perfectly, as then we could go from to without any issues. However, this is not possible as learning the distribution has too many possible solutions.
Instead, we attempt to learn a neural network that predicts the amount of noise that can be removed from to recover . And since we have the actual noise that was added to (), we can calculate the loss between the predicted noise and the actual noise, and update the neural network parameters to minimize this loss using backpropagation.
The neural network
In the original paper, the authors used a U-Net model with sinusodial positional encodings and self-attention as the backbone for the neural network.
The U-Net model is a popular choice for diffusion models as it takes an image as input, encodes it into a latent space, and then decodes it back into the original image, with the added benefit of skip connections that help in gradient flow during training. It is made up of a series of ResNet blocks, which itself is made up of a series of convolutional layers, group normalization layers, and SiLU activation functions. The image below shows the architecture of a U-Net model, taken from the original paper:

The sinusodial positional encoding helps the model share parameters across time, and understand what timestep it is currently predicting the noise for, as the self-attention blocks do not have any positional information. This idea was made popular in the paper "Attention is All You Need" by Vaswani et al. (2017)..
Loss function
The loss between the predicted noise and the actual noise is calculated using the mean squared error (MSE) loss function, which is defined as:
The training process tries to minimize this loss using gradient descent. In the original paper, the authors used the Adam optimizer with a learning rate of and a batch size of 128.
The training process can be visualized as:

This process of adding noise, predicting the noise that should be removed, and updating the neural network parameters is repeated multiple times until the neural network converges to a good solution, or until the training budget is exhausted (most likely the latter).
Sampling from the model
Training the model is only half the challenge. The other half is using the trained model to actually generate new images from random noise. I will talk about two methods to sample from the model, namely the method proposed in the original DDPM paper, and the method proposed as a faster alternative in the DDIM paper.
The next sections might get a bit technical, so feel free to skip them if you're not interested in the details. The GIFs shown below are from a model that I trained on CIFAR-10 for ~20 epochs (which is not enough for good quality images, but enough to understand the process) while writing this blog post.
The key takeaway is that to generate an image from a trained diffusion model, we start with a random noise tensor, and run the backward diffusion process in an autoregressive manner over the sequence (or a subset of the sequence) to generate the final image.
DDPM sampling
In this method, we start with a random noise tensor and run the backward diffusion process in an autoregressive manner over the entire timestep sequence to generate the final image. At each timestep , a part of the predicted noise is removed from the image , to get the image .
Mathematically, this is represented as:
where,
- is the noisy image at timestep .
- is the predicted noise that should be removed from
- is simply .
- is the cumulative product of , i.e., .
- is the standard deviation of the model, which the authors fix to either or . This was done more for simplicity, and the paper by Nichol & Dhariwal (2021) talks about learning this parameter as well.
- is a random noise tensor sampled from until the final timestep .
Visually, the process looks like this:
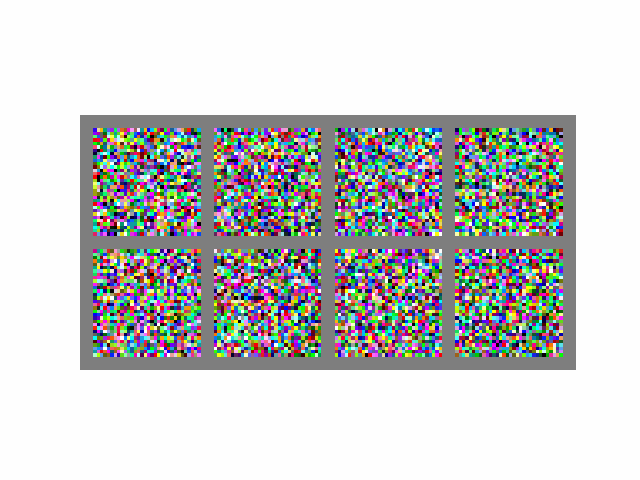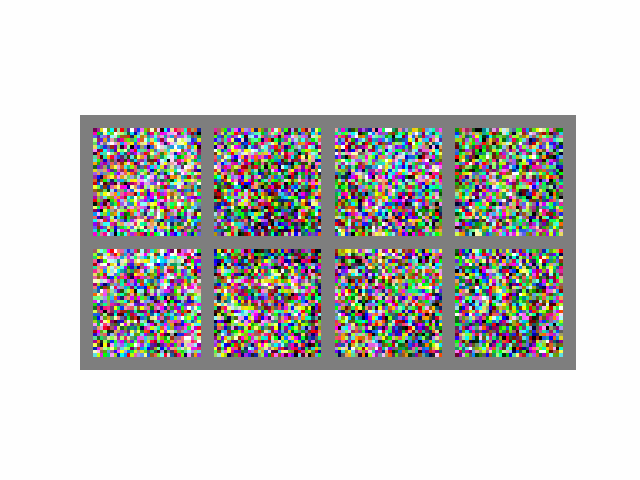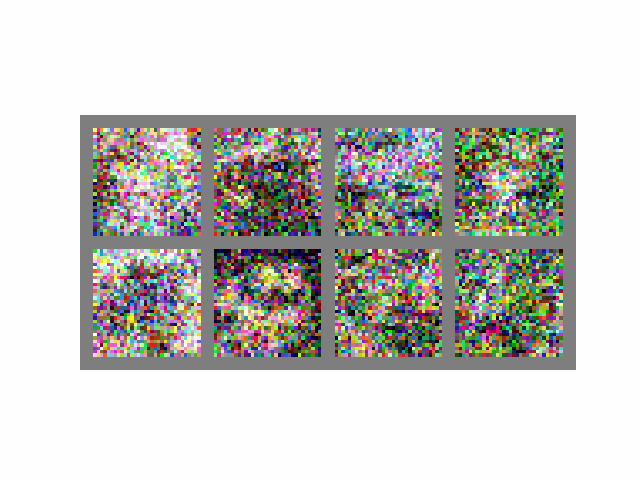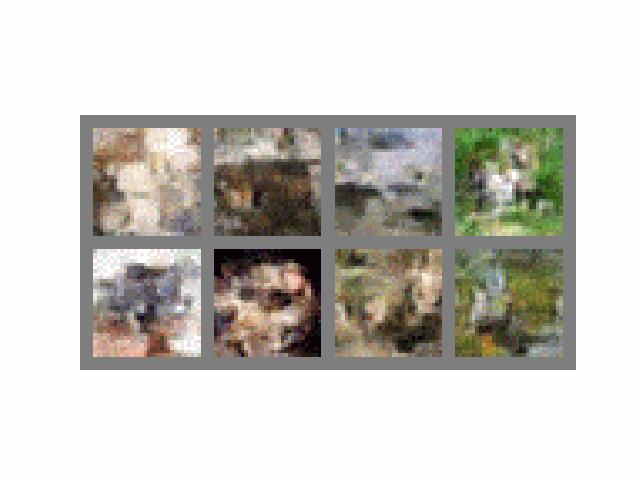
If we assume , then to generate a single batch of images, the above equation is computed 1000 times, which is quite slow. From Song et. al (2020), "it takes around 20 hours to sample 50k images of size 32 × 32 from a DDPM".
DDIM sampling
The paper "Denosing Diffusion Implicit Models" by Song et al. (2020) proposed a faster alternative to sampling from a model trained with the same objective as the DDPM model. The key idea they introduced is to have a new hyperparameter , which controls the amount of stochasticity in the sampling process. By setting , the sampling process becomes deterministic. Moreover, we do not need to follow the whole chain from to generate an image, but rather a subset () of the timesteps.
Mathematically, the DDIM process is represented as:
where,
- is a sub-sequence of timesteps, controlled by the hyperparameter .
- is the noisy image at timestep t.
- is the predicted noise that should be removed from
- is equivalent to in the DDPM sampling process, i.e., .
- is the hyperparameter that controls the amount of stochasticity in the sampling process.
From the above equations, we can see that the DDIM sampling process approximates the image at each timestep (the first term in the equation). The second term of the equation computes the direction pointing to the image, which allows this process to essentially skip a few timesteps. Finally, the last term of the equation adds a small amount of noise in the denoising step.
Visually, the process looks like this when :
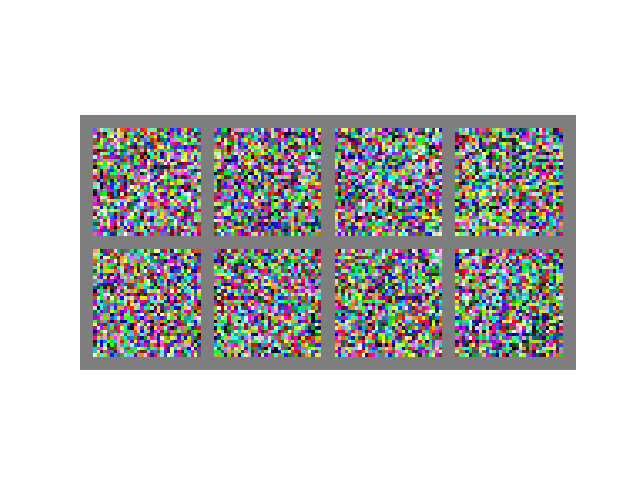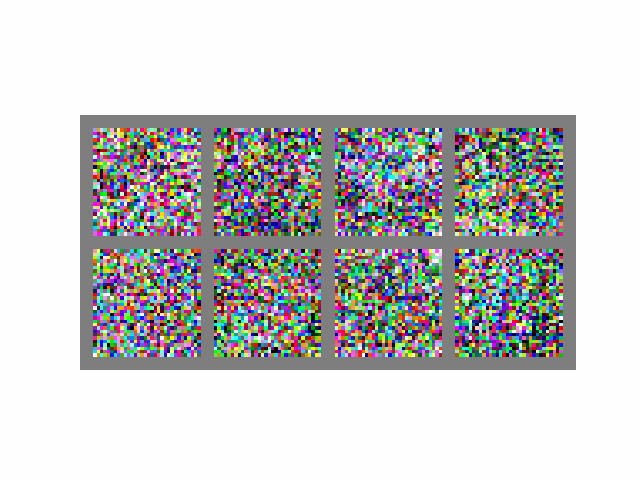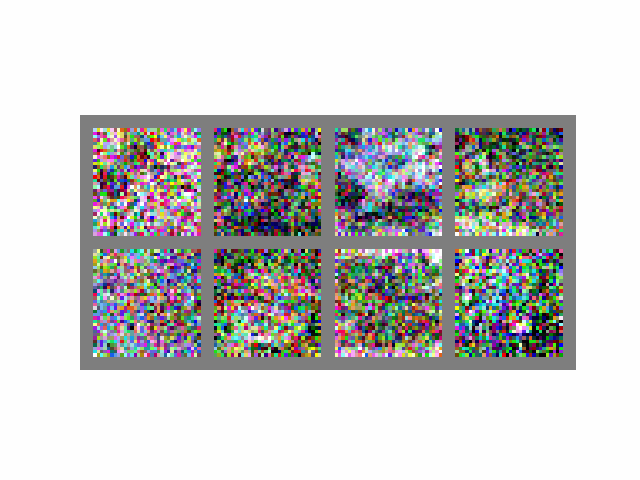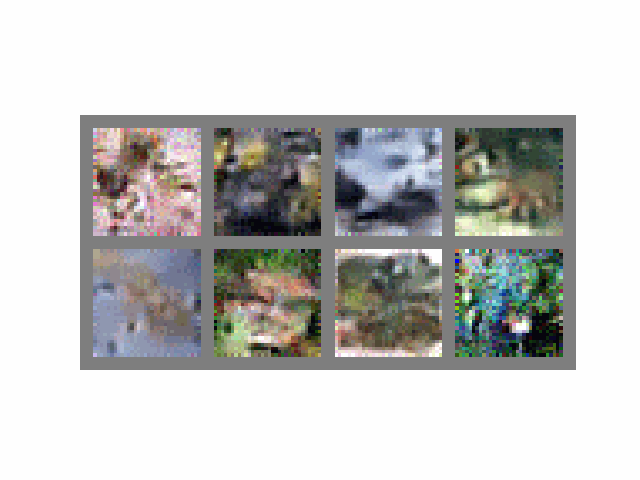
If we set , then the process becomes completely deterministic as the term becomes 0. At , we are back to the DDPM sampling process (the derivation is simple but lengthy, please see this article for more).
The choice between DDPM and DDIM sampling is a trade-off between speed and quality. DDPM sampling is slower but produces better quality images, while DDIM sampling is faster but produces slightly worse quality images. However, recent research has introduced even better methods such as latent diffusion models which run on a smaller latent space instead of the original pixel space.
Conclusion
I hope this blog post helped you understand the key idea behind the diffusion process, and how it is used to generate images. Although the original paper is now quite old as newer, better models have been introduced, I wanted to understand the basics first, before diving into the more advanced models.
The code to train a DDPM-based model on CIFAR-10 is available on my GitHub repository. Please feel free to reach out to me if you have any questions or suggestions. I would love to hear from you! I can be reached on X/Twitter, or LinkedIn.