Exploring GEPA and DSPy for AI system optimization
Background info on DSPy
- DSPy is a declarative framework for building language model (LM) systems. At its core, it provides a set of well-designed abstractions to build AI programs in a more "PyTorch"-oriented approach.
- It brings the idea of "prompt engineering" or "prompt optimization" to a much more manageable level of defining
signatures, which are the inputs and outputs of the program, rather than dealing with each individual token in the prompt. - A
modulein DSPy defines the program itself, and can be composed of other modules (ChainOfThought,ReAct, etc.) to build more complex programs. Together, these abstractions allow you to build systems in a more realistic way, and enable faster experimentation. - An
optimizerin DSPy allows you to train your program on a particular trajectory to improve your modules (and prompts) to perform better on certain tasks. This will be the focus of this post. - A simple DSPy program can be defined as:
import dspy
math = dspy.Predict("question -> steps: List[str], answer: str")
math(question="Two dice are tossed. What is the probability that the sum equals two?")
>>> Prediction(
steps=[
'There are 6 faces on each die, so the total number of outcomes is 6 * 6 = 36.',
'The sum of the numbers on the two dice equals two only when both dice show a 1. This is just one specific outcome: (1, 1).',
'Therefore, there is only 1 favorable outcome.',
'The probability of the sum being two is the number of favorable outcomes divided by the total number of possible outcomes, which is 1/36.'
],
answer=0.0277776
)
- There is a lot more to understand about DSPy, but I want to keep this post focused on GEPA. To read more about DSPy, I recommend checking out this blog post by Prashanth Rao.
What does "optimization" mean here?
The fundamental model of the current wave of AI software looks a lot like this:
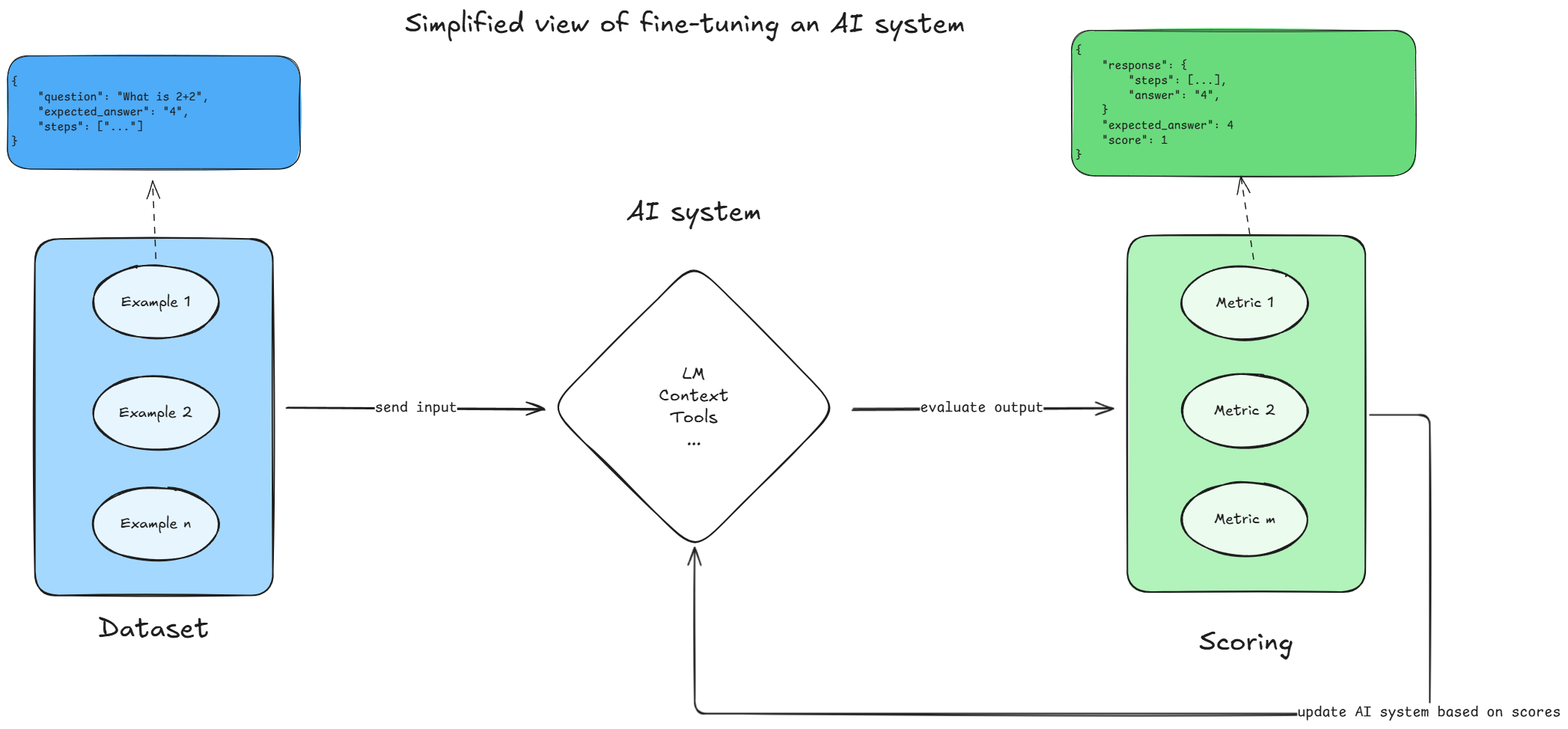
When you're building these systems, the work can broadly be split into:
-
Thinking about the system architecture:
- What are the inputs?
- What do I expect the output to be?
- What tools will I have to provide to the model?
- How do I measure success?
-
Building the system:
- What prompts should I write?
- What framework should I commit to?
- What model should I use?
- How should I format my tool results?
Most teams I observe spend a lot of their time on the second part, and not enough on the first part. In other words, a lot of time currently may be wasted on incremental improvements through manual prompt engineering, while the real work is in unraveling the complexity of the system architecture, which is only possible by starting simple and iteratively building up.
To that end, an AI system can be thought of as a set of three components:
-
Dataset: A collection of examples that comprehensively represent the set of tasks for the system. It can be represented as dictionaries containing any information required by the task. For example, HotpotQA, RealworldQA, etc.
-
Task: A program that maps input → output. This is where the optimization happens, either directly on the language model weights or in the prompts across the system.
-
Scorer: A function that provides a metric (and optionally feedback) for the task, based on an example and the corresponding output. A scorer can be simple, such as
exact_match(prediction, answer), or more complex, such as an LLM-as-judge rubric that asks another model to grade correctness.A natural question that arises here: Wait, how do I ensure that the LLM-as-judge is grading correctly? For the interested, I invite you to read the AlignEval article by Eugene Yan for an extremely comprehensive answer.
To summarize, optimizing an AI system can be viewed as a search over the task space, with guidance from the scorer.
What is GEPA?
GEPA, or Genetic-Pareto, is a sample-efficient optimizer based on three principles: Genetic evolution, Pareto filtering, and Reflection using natural language feedback.
From the paper:
 principles](https://pub-eea84c0df29e410c936b219e07b84bea.r2.dev/site-assets/blogs/gepa/gepa_overview.png)
The goal of the optimization process is to identify a set of prompts in the program that maximize the score over the tasks, constrained by a budget.
When GEPA starts, it initializes a candidate pool . Each candidate is a set of prompts to be used in the program, which means initially there is only 1 candidate in the pool. Iteratively, GEPA will propose new candidates by modifying existing candidates based on their previous states to accumulate lessons as the genetic tree evolves.
In each iteration, GEPA does the following:
- Selects the best candidate from the pool based on the score over the tasks (see Pareto filtering below)
- Generates a new candidate by modifying the selected candidate through reflection (usually a strong LM, such as
gpt-5-highorgemini-2.5-pro). In this step, feedback from previous generations is used to guide the reflection process, turning the evaluation trace into a diagnostic signal. - Evaluates the new candidate on a minibatch of tasks
- If the new candidate performs better than the selected candidate, the new candidate is added to the pool and it is evaluated on the full validation set
- Else, the new candidate is discarded and the process repeats until the budget is exhausted.
Pareto filtering
The sub-problem of selecting candidates in each iteration determines the "explore-exploit" tradeoff in the optimization process, which is an extremely crucial component of any decision making process. Strategies can range from purely exploitative (always selecting the best candidate) to purely exploratory (randomly selecting a candidate), with multiple intermediate strategies in between. Both extremes on this spectrum have significant drawbacks:
- A purely exploitative strategy may get stuck in a local optimum, as a dominant strategy will always be selected, giving no room for potentially better strategies.
- A purely exploratory strategy may not converge to a good solution, as it may spend too much time exploring inferior strategies.
The authors of GEPA employ a strategy that keeps only the best performers. For every training example, GEPA tracks the highest score any candidate has achieved so far, creating a "Pareto frontier" of scores. Then, it keeps only those candidates that hit at least one of these best scores to "filter" the pool down to candidates that have demonstrated success in some form. Candidates in the pool are then pruned based on dominance to prevent the pool from growing too large. Finally, GEPA randomly picks a candidate from the pruned pool, giving higher chances to those that achieved the most best scores.
This strategy helps escaping a local optimum, but also prevents excessive exploration.
Running GEPA on the CommonSenseQA dataset
To make things concrete, let's walk through a simple example of running GEPA on a toy dataset. I urge you to follow along for maximum knowledge retention. You can find the full code here.
Dataset
I'm using the CommonSenseQA dataset, which contains a question with multiple choices.
A sample of the dataset is shown below:
{
"question": "The sanctions against the school were a punishing blow, and they seemed to what the efforts the school had made to change?",
"choices": {
"label": ["A", "B", "C", "D", "E"],
"text": ["ignore", "enforce", "authoritarian", "yell at", "avoid"]
},
"answerKey": "A"
}
The dataset contains three splits: train, validation, and test. Since the test split does not contain the actual labels (for preventing leakage), I will not be using it for this post. Instead, the validation split will act as the test set, while the train split will be split into training and development sets.
train_dataset = [
dspy.Example(**d).with_inputs("question", "choices") for d in dataset["train"]
]
test_dataset = [
dspy.Example(**d).with_inputs("question", "choices") for d in dataset["validation"]
]
random.Random(1).shuffle(train_dataset)
# Taking a smaller subset for quick testing
trainset = train_dataset[:300]
devset = train_dataset[300:600]
testset = test_dataset[:100]
Task
The task here is direct:
Given a question, select the correct answer from the multiple choices.
In DSPy, this program can be written as:
class CommonSenseQA(dspy.Signature):
"""Based on the question and the multiple choices, select the correct answer."""
question: str = dspy.InputField()
choices: str = dspy.InputField()
answer: str = dspy.OutputField(description="The correct label of the answer")
program = dspy.ChainOfThought(CommonSenseQA)
Scorer
The scorer is also straightforward. We can compare the model's predicted answer with the label field in the dataset and assign a score of 1 if they match, otherwise 0. Since we will be using reflection to guide the prompt mutation, we can return natural language feedback depending on the score:
def metric_with_feedback(
example: dspy.Example,
pred: dspy.Prediction,
trace=None,
pred_trace=None,
pred_name=None,
):
try:
score = 1 if pred.answer == example.answerKey else 0
except Exception as e:
feedback_text = dedent(
f"""
There was an error in processing the answer: {e}. Please ensure that you follow the instructions carefully.
"""
)
return dspy.Prediction(
score=0,
feedback=feedback_text,
)
feedback_text = dedent(
f"""
You chose the {"correct" if score == 1 else "incorrect"} answer!
Correct answer: {example.answerKey}
"""
)
return dspy.Prediction(
score=score,
# This feedback will be sent only to the reflection LM for mutation
feedback=feedback_text,
)
Inference provider and models
With the three components defined, we can now set up inference. DSPy integrates with LiteLLM to support a wide range of inference providers. For this example, I used a single A100 GPU instance on PrimeIntellect as my provider. A brief set of instructions to set up the instance can be found in the appendix below.
For both the base model and reflection model, I chose Qwen/Qwen3-8B to prioritze speed. While using a more powerful model for reflection can potentially improve performance, the actual benefits depend heavily on the specific task. Here's how to configure the models in DSPy:
lm = dspy.LM(
"openai/Qwen/Qwen3-8B",
api_base="http://localhost:8000/v1",
api_key="API_KEY",
temperature=None,
max_tokens=4096,
)
dspy.configure(lm=lm)
To ensure everything is working, we can run a simple query:
response = program(
question="How do you wash pillows?",
choices={
"label": ["A", "B", "C", "D", "E"],
"text": ["Warm water and gentle cycle", "Warm water and normal cycle", "Cold water and gentle cycle", "Cold water and normal cycle", "None of the above"]
}
)
print(response)
>>> Prediction(
reasoning="The correct approach involves using a gentle cycle for washing pillows to avoid damaging the fabric or filling to prevent damage.",
answer="A"
)
If you've made it this far, then congratulations! You've successfully made a simple AI system. Next, let's run the optimization process.
Running the optimization
While GEPA offers a nice adapter to pair with any existing system, using it in DSPy is the easiest and recommended way to get started.
from dspy import GEPA
optimizer = GEPA(
metric=metric_with_feedback,
auto="light",
num_threads=64,
track_stats=True,
reflection_minibatch_size=16,
reflection_lm=lm,
)
optimized_program = optimizer.compile(
program=program,
trainset=trainset,
valset=devset,
)
With this, you should see the optimization process begin. After a few minutes (or hours), the optimized_program will contain an updated set of instructions that should hopefully perform better on the test set than the baseline program.
Results
I have deliberately kept the dataset size and number of iterations in the notebook small to finish the run quickly for this post. Therefore, the actual performance results are highly directional and not worth reporting. However, we can see the baseline and updated prompt side by side:
Baseline Prompt
Based on the question and the multiple choices, select the correct answer.
Updated Prompt
Based on the question and the provided multiple-choice options, select the correct answer by following these steps:
- Understand the Question's Intent: Identify the core purpose of the question (e.g., factual knowledge, contextual inference, logical reasoning, or common-sense understanding).
- Analyze Contextual Clues: Look for keywords, implied meanings, or situational details in the question that narrow down the correct answer (e.g., "devastating injury" in Example 2 suggests extreme negative descriptors).
- Evaluate Each Option:
- Relevance: Determine if the option directly addresses the question's focus.
- Nuance: Consider subtle differences in phrasing (e.g., "grotesque" vs. "hideous" in Example 2).
- Domain Knowledge: Apply specific factual knowledge (e.g., "motel" as a standard accommodation in Example 3).
- Eliminate Irrelevant Options: Discard choices that are unrelated, vague, or logically inconsistent (e.g., "hardware store" in Example 8).
- Prioritize Specificity: Choose the most precise answer when multiple options seem plausible (e.g., "river bed" over "creek bed" in Example 4, depending on context).
- Avoid Common Pitfalls:
- Do not assume overly broad categories (e.g., "play sports" is more general than "play ball" in Example 11).
- Avoid overgeneralizing (e.g., "lose money" is more accurate than "using money" in Example 15).
- Ensure alignment with standard terminology (e.g., "flashlight" as a portable light source in Example 5).
Key Domain-Specific Considerations:
- Recognize standard practices (e.g., "main street" for visibility in Example 14).
- Understand activity-specific contexts (e.g., "stones are found in river beds" for skipping in Example 4).
- Apply economic or social concepts (e.g., "raising interest rates" to combat inflation in Example 9).
As we can see, the updated prompt from just the first iteration shows a lot of detailed instructions, based on the training data used in the optimization process. There seems to be a risk of overfitting here, but if the validation set is different from the training set and approximates the downstream tasks, this risk is reduced as new prompts are only accepted if they perform better on the validation set.
The authors of the paper show a nice comparison of GEPA with other optimizers, including GRPO.
Conclusion
I hope this post was helpful in understanding the basics of DSPy and what GEPA is. If you followed along, I would love to see your results! If you have any questions, please reach out. The source code for this post can be found here.
Thanks for reading! If you would like to chat more about how these tools can help you build better systems, or just discuss generally about the whole space, hit me up on X/Twitter or LinkedIn.
References
- DSPy tutorial: GEPA for AIME
- GEPA paper
- GEPA implementation
- Learning DSPy 1: The power of good abstractions
- Learning DSPy 2: Understanding the internals
Appendix
Setting up a PrimeIntellect instance
To set up a PrimeIntellect instance for serving a language model, you can follow a detailed guide here. For a quick overview, see below:
-
SSH into your deployed instance, making sure to forward your ports to your local machine. There are a number of ways to secure this, and a quick search online should help you find a solution.
-
Run the install script (from here):
curl -sSL https://raw.githubusercontent.com/PrimeIntellect-ai/prime-rl/main/scripts/install.sh | bash
-
Restart your terminal session. Usually, just
bashwill do the trick. -
Create your
infer.tomlfile with your model configuration. For example:
[model]
model = "Qwen/Qwen3-8B"
max_model_len = 16384
- Run the inference server:
cd /prime-rl
uv run inference @ <path-to-your-infer.toml>
- You should now have a FastAPI server running at
http://localhost:8000/v1. If the port forwarding was set up correctly, the code provided above should work.
