TL;DR: LLM orchestration is challenging, as with any new technology. LangChain is a powerful framework that provides a way to manage the different components of an LLM application. It consists of a core protocol (LCEL,
langchain_core), multiple integrations (langchain_community), and a set of architectures (RAGs, LangGraph, LangSmith, LangServe).
We (as humans collectively) have done software for over 20 years now. There are a few established practices that are accepted as the norm. Large Language Models (or LLMs) provide a powerful new avenue to build the next generation of software (sometimes called Software 3.0). However, that does not mean we need to start from scratch. This post is meant to serve as a gentle introduction to LangChain and its components. But before we get there, we need to understand the need for LangChain in the first place.
I expect the reader to have some understanding of how LLM applications work. I will try and avoid jargon as much as possible. In brief,
you provide a prompt to a model, and it generates a response.
That's the ground-level idea. Every word in the idea above can be tweaked and made more complex, but the core idea remains the same. I really like this tweet from Hamel Husain that cuts through the overly technical jargon.

What is [LLM] orchestration?
From Databricks,
Orchestration is the coordination and management of multiple computer systems, applications and/or services, stringing together multiple tasks in order to execute a larger workflow or process. These processes can consist of multiple tasks that are automated and can involve multiple systems.
In simpler terms, an orchestration is like a conductor in an orchestra, with the orchestra being the various components of a system. In the context of LLMs, this becomes even more important because of a few reasons:
- All major LLM providers (private and open-source) do not provide a standardized interface to their models
- Connecting to enterprise systems and databases in a secure and scalable manner is challenging with the non-deterministic nature of LLMs
- Validating and evaluating the output of LLMs is not straightforward.
For a better understanding, look at this image from a16z: 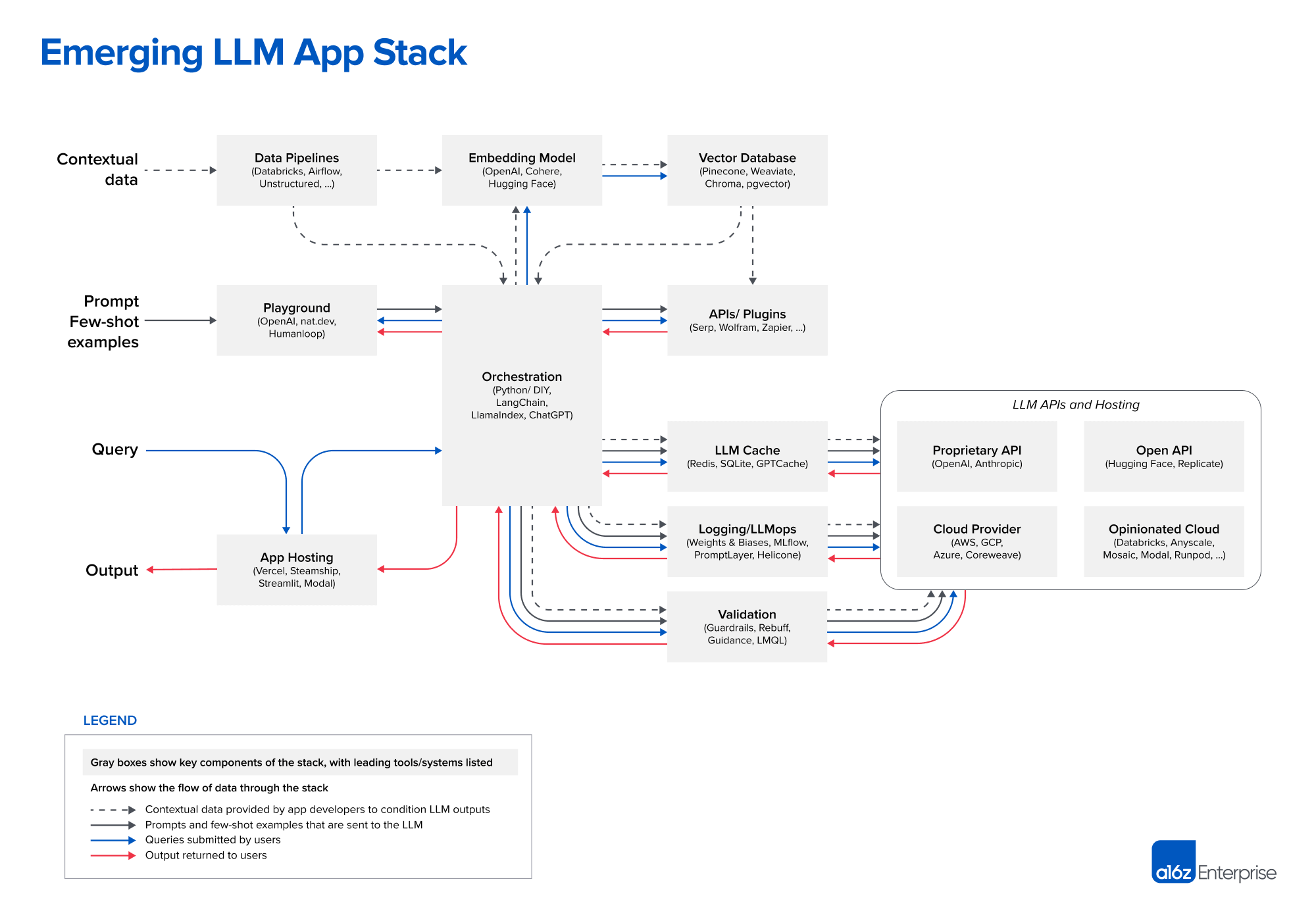
I do not expect you to understand everything in the image (it's a lot). The key takeaway is that there are multiple components with an orchestration block in the middle that connects everything.
But why can't I write an orchestration engine myself?
You absolutely can, and I recommend you do so for a toy project or a proof of concept. However, if your project needs to be reliable, scalable, and maintainable, then you need to provide parallelization, fallbacks, batch, stremaing, async, and more such concepts that Software 2.0 has perfected over the years.
This is where you add in tools such as LangChain or Microsoft Semantic Kernel.
What is LangChain?
Here, I'm going to give an overview of LangChain, primarily for 2 reasons:
- The industry is gradually converging on it as the standard for LLM orchestration. It averages 1M+ installs per month, while similar tools barely reach 100k+.
- I've been using it since 2023 and have seen it evolve from a simple wrapper to a full-fledged toolkit - seriously, massive props to Harrison Chase and the entire LangChain team.
As I explained above, LangChain is a framework to manage the different components of an LLM application. The entire stack, as shown on their website is: 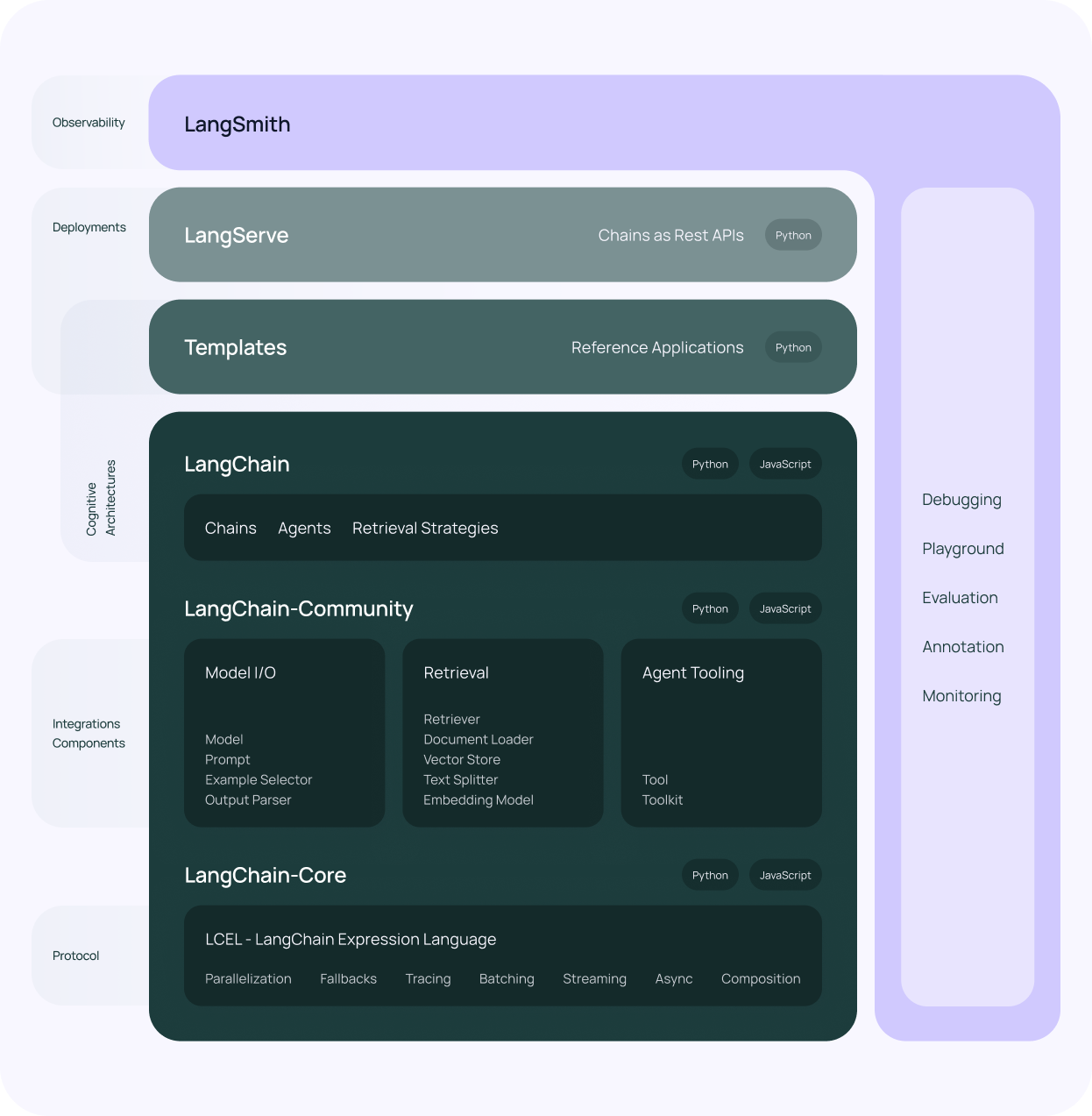
Again, it's a lot, but the key takeaway is that the stack comprises interoperable and interconnected components:
- A core protocol: This is the backbone, called the LangChain Expression Language (LCEL)
- Multiple integrations: These are connectors to different models, prompt templates, databases, etc.
- Set of architectures: These are different ways to structure the application, such as a single chain, multiple chains, single agent, etc.
In addition, LangChain also consists of 2 highly desirable add-ons, which I'm not going to cover in detail here:
- LangSmith: A all-in-one observability platform, think of it as a magnifying glass to see what's happening inside your application.
- LangServe: A one-click deployment engine that turns LangChain applications into a RESTful API.
What is LCEL?
In one line, LCEL is a way to declaratively combine LangChain components to create "chains". For example,
lcel_chain = prompt_template | openai_model | str_output_parser
This one line of chain will take a user input, pass it to the OpenAI model, and then parse the output into a string. This is a very simple example, but you can imagine how complex these chains can get. The chain can be used to stream tokens as they are generated, which means that your users can see the output in real-time, reducing the time-to-first-token.
The 3 methods in LangChain
Based on their website, LangChain has 3 main architectures to build applications that work across the stack: Retrieval, Agents, and Evaluation.
Retrieval
What is RAG?
I'm sure you've heard of the term "RAG" or "retrieval-augmented generation" thrown around multiple times. In a non-technical language, it is a way to add context to the prompt you provide to the model so that it generates a more relevant response. This context can be taken from a document, a website, or any other source of information.
Now, how does the model know which document to look at, and specifically which part of the document to look at? This is where we enter into the realm of embeddings, vectorstores, similarity scores, and more such concepts, which I'll cover in a later post.
Let me explain it with a diagram:
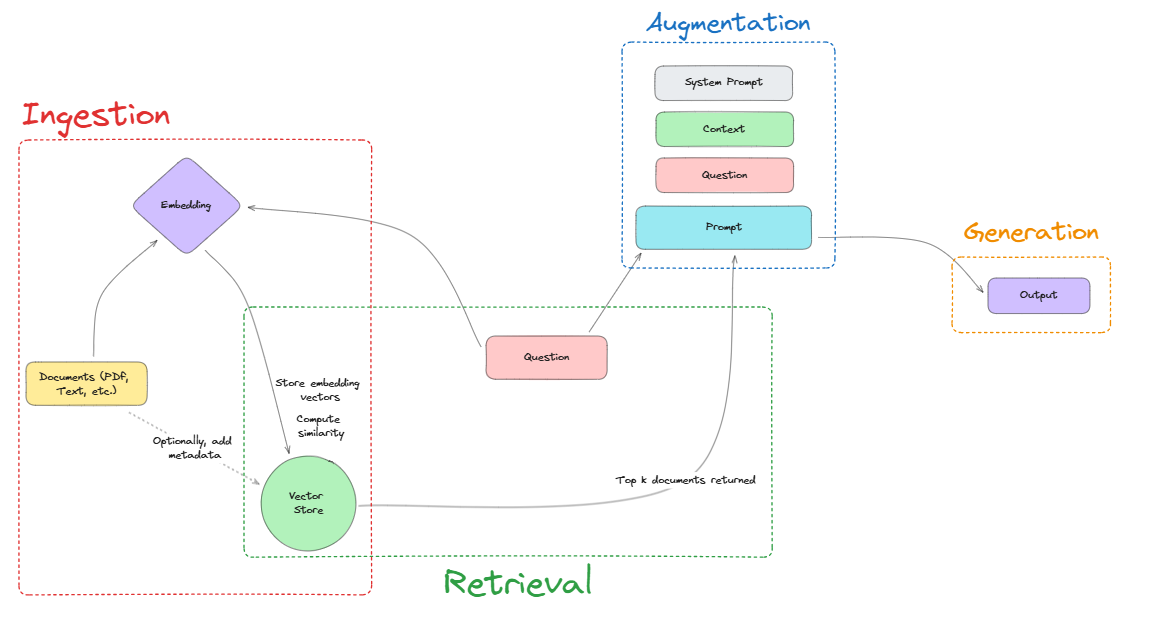
The process is broken down into 4 steps:
- Ingestion: This is where all the relevant documents are ingested into the system by chunking them, converting them into embeddings and storing them in a vectorstore. Note that the documents can either be provided or dynamically fetched, depending on the use case.
- Retrieval: Now, when a user provides a prompt, it passes through the retrieval component, which fetches the most relevant document from the vectorstore. At this point, the retrieval component can also fetch multiple documents and rank them based on relevance, or do more complex operations.
- Augmentation: The retrieved context is then passed into the augmentation component, which combines the prompt and the context to create a new prompt. This new prompt is then passed to the model.
- Generation: Finally, the model generates a response based on the new prompt.
That's all there is to RAG. As before, all the 4 steps above can be tweaked and made more complex, leading to more powerful applications.
RAG in LangChain
LangChain offers an extensive library of tools and an intuitive framework to compose the components of a RAG system, mostly contributed by the community. Let's look at the same example from before, but using the stack:
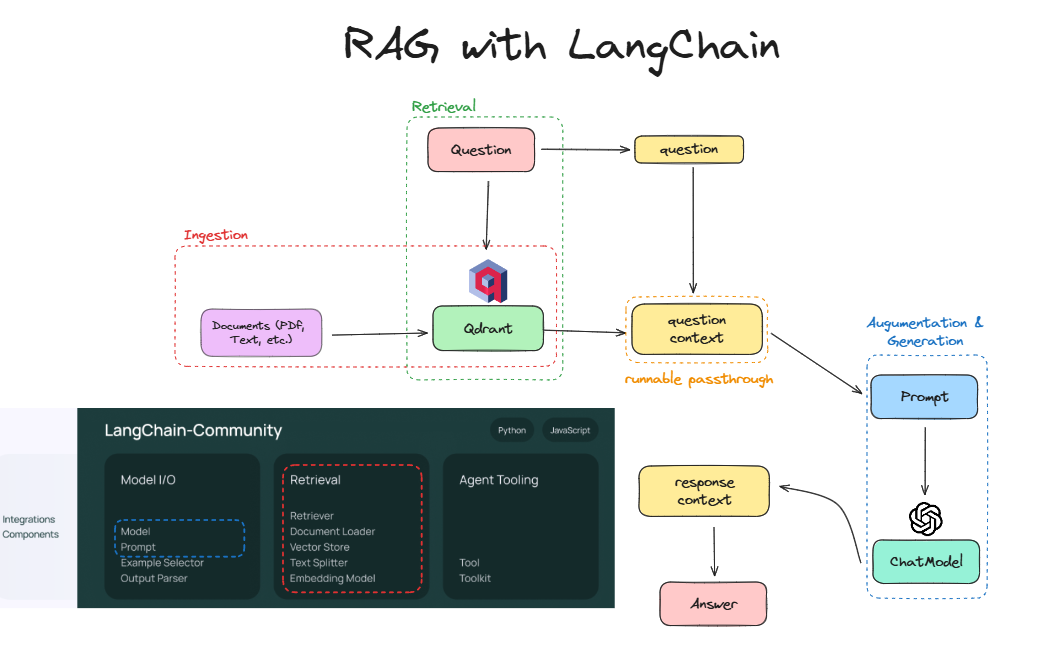
Notice how the core idea is the same: I'm still ingesting and retrieving documents, augmenting the prompt, and generating a response. The difference is that now I'm using:
- Qdrant as a vectorstore to ingest and store the embedded documents. Read more here
- LCEL Runnables to write in LCEL the retrieval, augmentation, and generation components
- OpenAI Models to connect to an external embedding and language model.
The benefit I want to highlight is that everything is connected through LCEL, which means that I can swap out any component with another one that adheres to the LCEL protocol, be it a different vectorstore, different model, different prompt template, different retrieval strategy, different document sources, etc. Having an extensible and interoperable stack unlocks a lot of possibilities.
Agents
So now we've made an application that can augment prompts with information from documents. But what if we want to provide this application with reasoning or planning capabilities, or give it the ability to call external functions like getting the weather or sending an email? This is where Agents come in.
From the LangChain docs:
Agents are systems that use LLMs as reasoning engines to determine which actions to take and the inputs to pass them. After executing actions, the results can be fed back into the LLM to determine whether more actions are needed, or whether it is okay to finish.
Essentially, agents are chains wrapped with conditional statements and for/while loops:
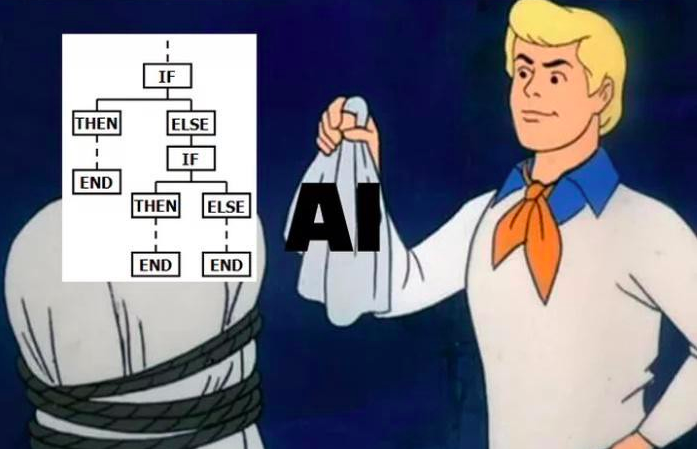
While the above isn't exactly true, it does have a grain of truth in it. The good news is that we already have an understanding of how we can create the "THEN" blocks. What's left is to understand how we can create the "IF" and "END" blocks.
Agents in LangChain
LangChain provides the functionality to build agents through LangGraph. At the risk of sounding like a broken record, LangGraph is a way to declaratively combine LangChain components and other functions to create "graphs". It achieves this by providing nodes and edges that can be connected and have a common, shared state.
A key point of difference is that LangGraph is not a Directed Acyclic Graph (DAG), meaning that you can have loops in your graph.
Let's look at an example application made with LangGraph:
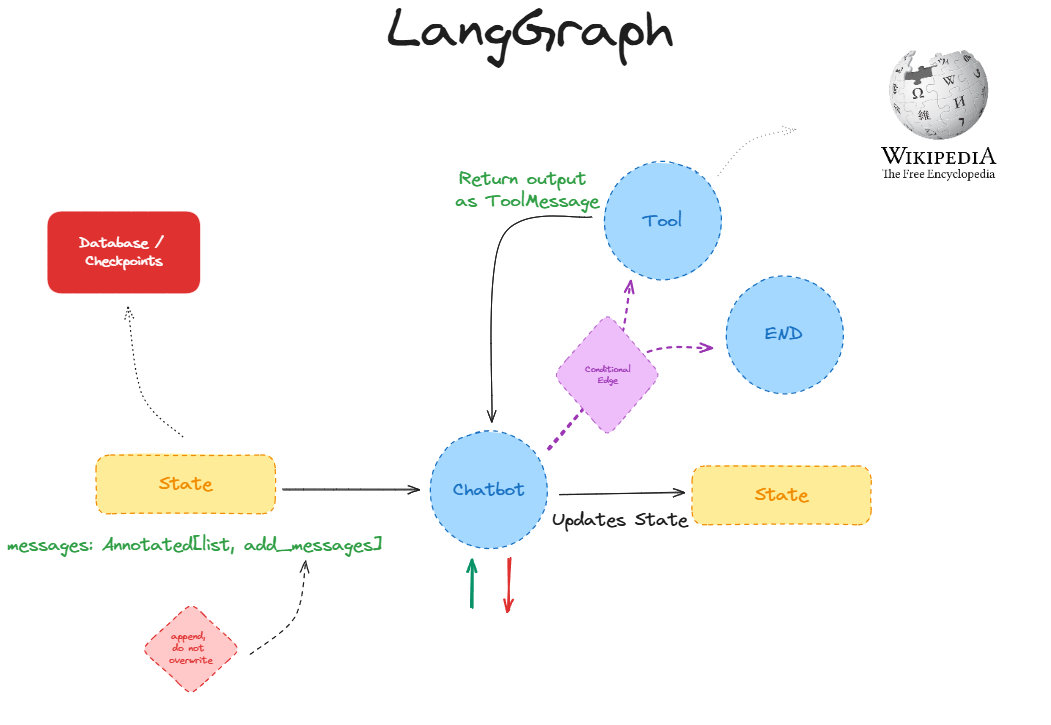
I'll spare the technical details, which you can understand from this tutorial here. Here are the key takeaways:
- The nodes are represented in blue. There's 3 nodes here: Chatbot, Tool, and END
- Chatbot is the LLM model that is responsible for converting the user input into a next step
- Tool is an external function that can be called by the chatbot. In this example, it's a Wikipedia search function
- END denotes the end of the graph
- The "normal" edges are represented in black. There's only 1 edge of this type, which connects the Tool to the Chatbot, meaning that whenever the Tool executes, all output is sent to the Chatbot
- The "conditional" edges are represented in purple. A conditional edge allows the agent to take different paths based on the output of the previous node. In this example, the Chatbot can either go to the Tool or the END node based on the user input and the agent's reasoning.
- The state represents the information that every node in the graph has access to. It also defines how each node can modify the state. In this example, the state contains a list of messages, and each node can only append to this list.
- Finally, we provide memory to the agent through a database that stores the state of the graph after every step. Another key feature here is that the memory is controlled using threads, which means that the agent can run separate threads for separate users.
I think LangGraph is extremely powerful, although it is complicated to understand conditional edges and state management. I'll keep exploring this and provide more insights in a future post.
Evaluation
All of what I've described above is actually pretty useless if you don't know how well your application is performing. Moreover, LLMs are inherently non-deterministic, meaning that the same input will not always produce the same output. By application performance, I mean each and every component of the application, from the prompt templates to the retrieval strategies to the agent behavior.
Having a proper evaluation framework, such as Metrics-Driven Development, is the cornerstone of building reliable and scalable applications. This can be as simple as measuring the effectiveness of different prompts, or become more complex by measuring the impact of different retrieval strategies on the model's performance, latency, throughput, etc.
Evaluation with LangSmith
LangSmith is a one-stop observability platform to develop, collaborate, test, and monitor LLM applications. What's super cool about LangSmith is that it integrates with all LangChain components off-the-shelf, and can even be configured to work with non-LangChain components.
I won't go into the details of LangSmith here, but I will link this great tutorial series by Lance Martin on how to use LangSmith. I'm going through it myself and learning so much.
Conclusion
I hope this post has given you a good overview of LangChain and its components. I've tried to keep it as non-technical as possible, but I understand that some parts might be hard to grasp. I'll be writing more posts on how to use all these components to create powerful applications, so stay tuned!
I'm currently about to graduate from my Master of Management in Analytics program at McGill University, and am actively seeking full-time opportunities in data science and artificial intelligence. Please feel free to reach out via LinkedIn, X, or e-mail if you have any questions or just want to chat!