
While learning about LLMs and the entire lifecycle, I wanted to do some evaluations myself to understand the concepts better and get a hands-on experience.
This post will walk you through some setup and inital evaluations I did on a 10-K financial dataset using LangSmith. I used edgartools to access the SEC EDGAR database programmatically, load the 10-K filings, chunk and embed them into a Supabase pgvector database, and then use metadata filtering to evaluate two models (gpt-4o and gpt-3.5-turbo) with varying levels of k for the retrieval task. Huge shoutout to Virat Singh for the amazing financial-datasets package, where I derived a lot of inspiration from.
Setup
Accessing SEC EDGAR Database
Using edgartools, I wrote a few functions to provide the ticker, year, type of filing, and the type of items to extract from the 10-K filings. This allowed me to call a function and get the relevant document strings for the given parameters.
items = get_company_items(ticker="NVDA", year=2023, form="10-K", item_names=["Item 1", "Item 7"])
I opted for Item 1 and Item 7 (Business and Management's Discussion and Analysis) as they are usually the most text-heavy sections of the 10-K filings.
Chunking and Embedding
For my vectorstore, I opted to use a pgvector database on Supabase. Why? Because I think it's simple to use for small-scale projects, and it's easy to use (more here).
I opted to use text-embedding-3-small with 512 dimensions for the embedding model, and chunked the documents, adding them to the database with metadata.
documents = chunk_documents(items, ticker="NVDA", year=2023)
vectorstore.add_documents(documents)
Inference
Creating the chain
This part was a little tough to figure out from the LangChain documentation, but I realized that I simply had to use a RunnableLambda to create a custom retriever that I could perform metadata filtering with.
After it, it was just a matter of using LCEL to construct a chain that I could call invoke on and get the results (see source notebook for more details).
question = "What is the company's policy on inventories?"
print(chain.invoke({"question": question, "ticker": "COST"}))
A quick glance at the LangSmith trace showed me the chain was working as expected with the current prompts and configurations.
Evaluations
Loading the evaluation dataset
After trying to build a dataset by manually prompting the chain, I realized that I could use a pre-built dataset on the same source documents using the financial-qa-10K dataset from HuggingFace. I sampled 50 questions from those tickers that I had loaded in my database:
tickers_loaded = ['NVDA', 'LULU', 'AAPL', 'MSFT', 'COST', 'TSLA']
sampled_ds = filtered_dataset.sample(n=50, random_state=42)
Here's a sample row:
INPUT:
Ticker: NVDA
Question: Who are NVIDIA's primary suppliers for semiconductor wafer production?
OUTPUT:
Answer: NVIDIA's primary suppliers for semiconductor wafer production ...
Contexts: <Chunk 1>, <Chunk 2>, ..., <Chunk k>
Running the evaluations
Before running the evaluations, I had to learn and understand more about a few metrics that I could use. For that, I found this tutorial by RLanceMartin extremely helpful.
Answer correctness
This metric measures the correctness of the answer given by the model, using the actual answer from the example as the ground truth.
Answer hallucinations
This metric measures the accuracy of the answer given by the model with the retrived context to quantify the share of hallucinated answers. This is important because it helps us understand if the model is generating answers that are not present in the context.
Document relevance
This metric measures the relevance of the retrieved context items to the question to quantify the performance of the retrieval. I'm also interested in trying to calculate context precision and context recall.
Experiment setup
After defining the above metrics using LangChainStringEvaluator, I ran the evaluations on a range of k values with two models: gpt-4o and gpt-3.5-turbo for n=5 times.
k_values = [1, 2, 5, 7, 10, 15]
models = ["gpt-4o", "gpt-3.5-turbo"]
evaluate(
chain,
data="10K-huggingface-dataset",
evaluators=[answer_correctness, answer_hallucinations, document_relevance],
experiment_prefix=f"10k-hf-50-k{<k>}",
num_repetitions=5,
metadata={
"model": <MODEL>,
"temperature": 0.6,
"embedding": "openai/text-embedding-3-small",
"vectorstore": "supabase",
"k": <k>,
"embedding_dimensions": 512,
"chunk_size": 1024,
"chunk_overlap": 100,
},
)
This ran 12 experiments, each with 5 repetitions, for 50 rows of the dataset. That caluclates to 12 * 5 * 50 = 3000 evaluations in total, with varying input prompt lengths due to the k values.
That feels like a lot of evaluations, with
gpt-4oandk=15costing $5.09 to run. This also tells me that evaluations can get expensive quickly, and therefore, it's important to decide on the frequency of evaluations, along with the type of evaluations to run (taken from Hamel Husain's blog).
Results
Here are the results of the experiments:
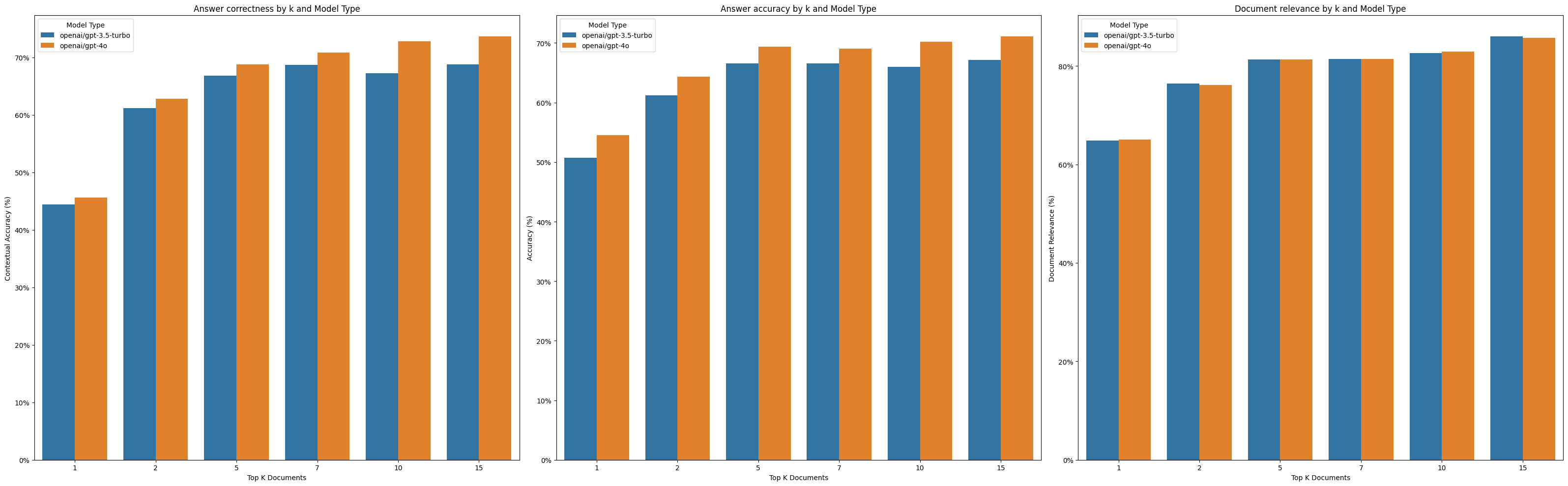
As expected, higher values of k improve performance for both correctness and accuracy. The gpt-4o model outperforms gpt-3.5-turbo in all metrics, which is expected given the huge gap between the two models (weird, it's only been a year?).
But, of course, this comes with a cost:
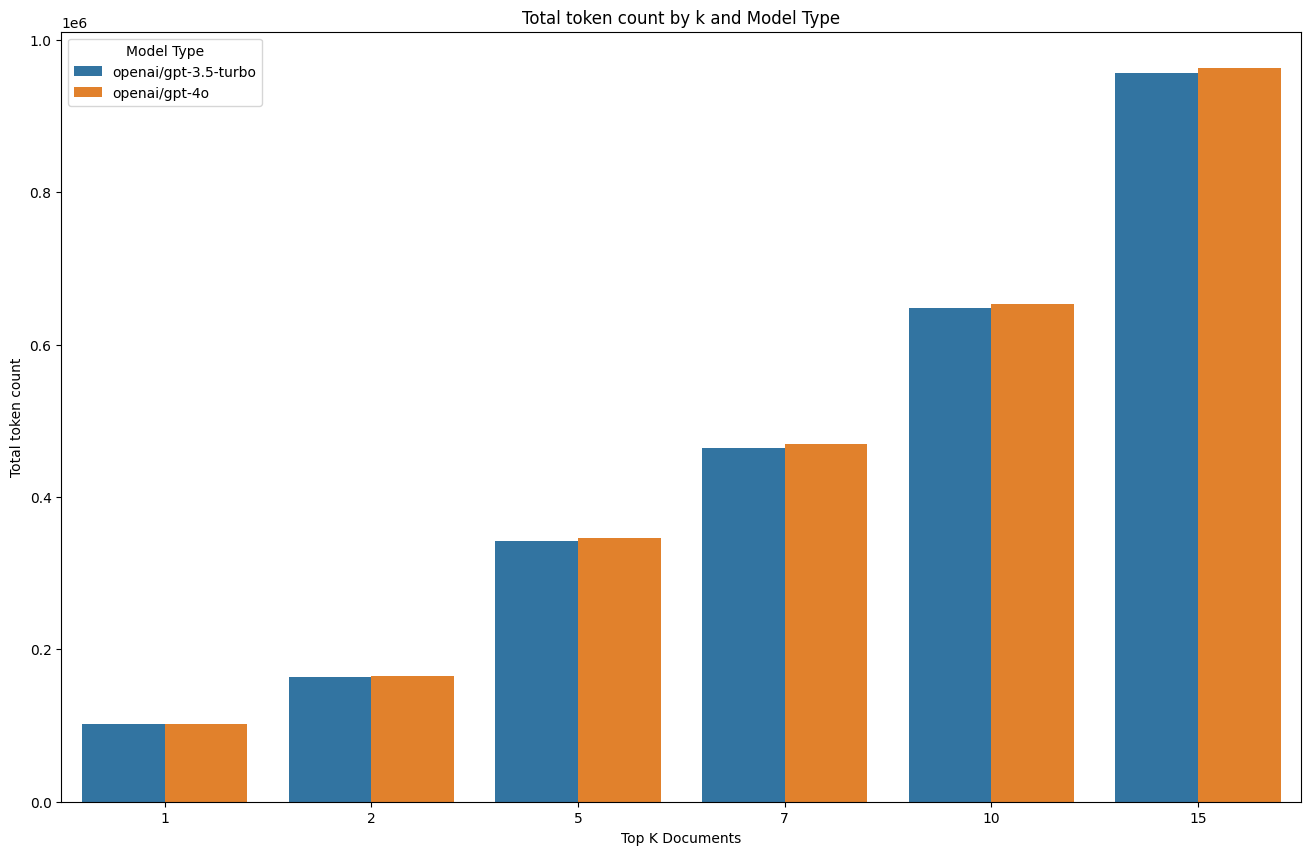
The token count increases with k, as more context is fed into the prompt. This highlights the tradeoff between performance and cost, and the need to find the right balance for the task at hand, which differs for each use case.
Extensions
I plan to extend this evaluation to other aspects of the process, such as chunking, embedding, reranking, prompts, and more. This will also be a great opportunity to experiment with LCEL and understand the ecosystem better.
Another possible extension is to update the metadata filtering to be through query generation, which would allow for more flexibility in the retrieval process when scaling up.
The whole process flow so far looks like this:
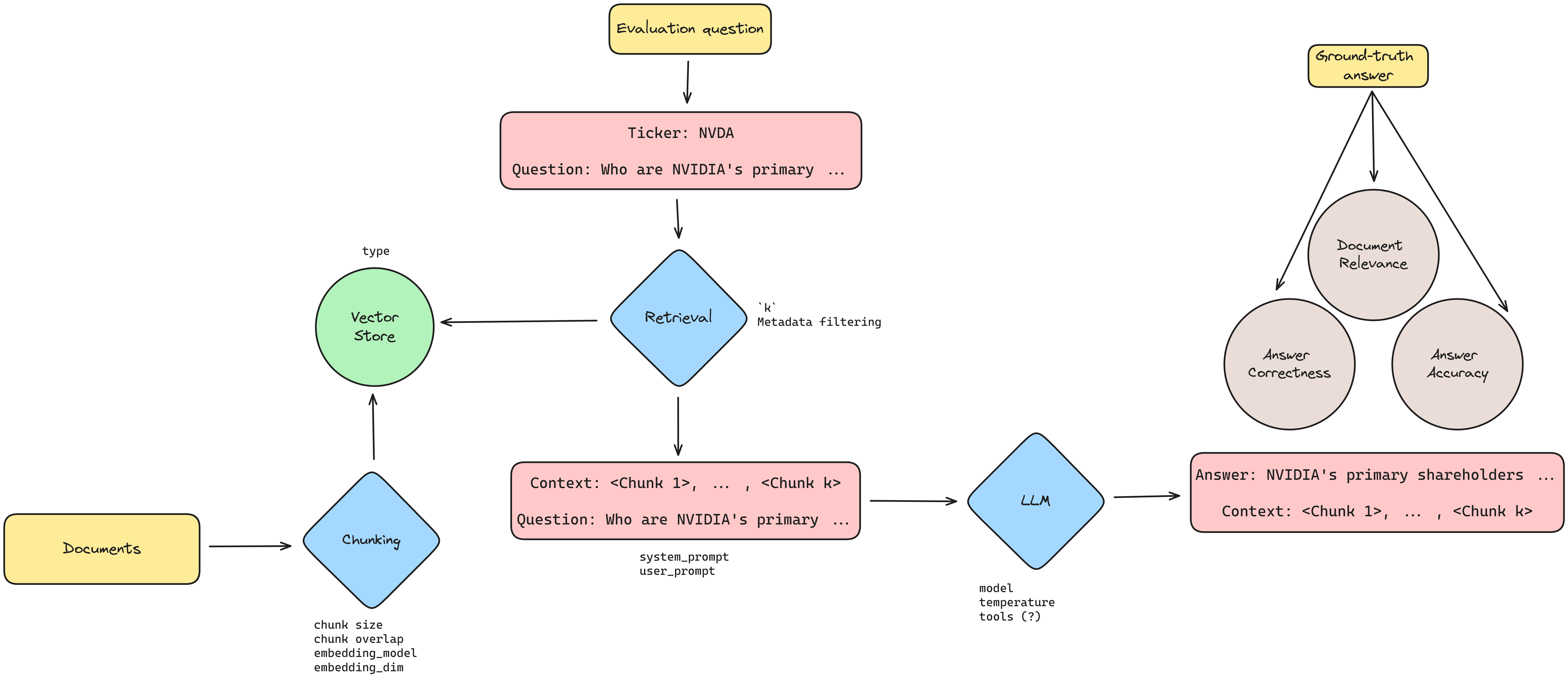
I've tried to list out all the possible hyperparameters I could think of, but I'm sure there are more that could be evaluated. For a more comprehensive read, check out Jason Liu's blog post on the levels of complexity in RAG applications.
The notebook can be found here.
Stay tuned for more updates!