Building RL environments for open-source AGI
Background and quick summary
- Reinforcement learning (RL), if you zoom out far enough (or zoom in?), is a type of machine learning that involves an agent learning to interact (take actions) in an environment to maximize a reward signal.
- RL has existed far, far before the current hype, and is multi-disciplinary, involving ideas from control theory, optimization, statistics, and more.
- Applied to the world of Language Models (LMs), both large and small, it offers a way to provide a LM with actions in that environment, and a way to evaluate it based on reward signals.
- From @karpathy:
Environments have the property that once the skeleton of the framework is in place, in principle the community / industry can parallelize across many different domains, which is exciting.
In this post, I talk about:
- What an environment is
- My understanding of
verifiers - How I helped port a couple of benchmarks to PrimeIntellect's Environment Hub
- Running my own inference server with
Qwen/Qwen3-0.6B
What is an environment?
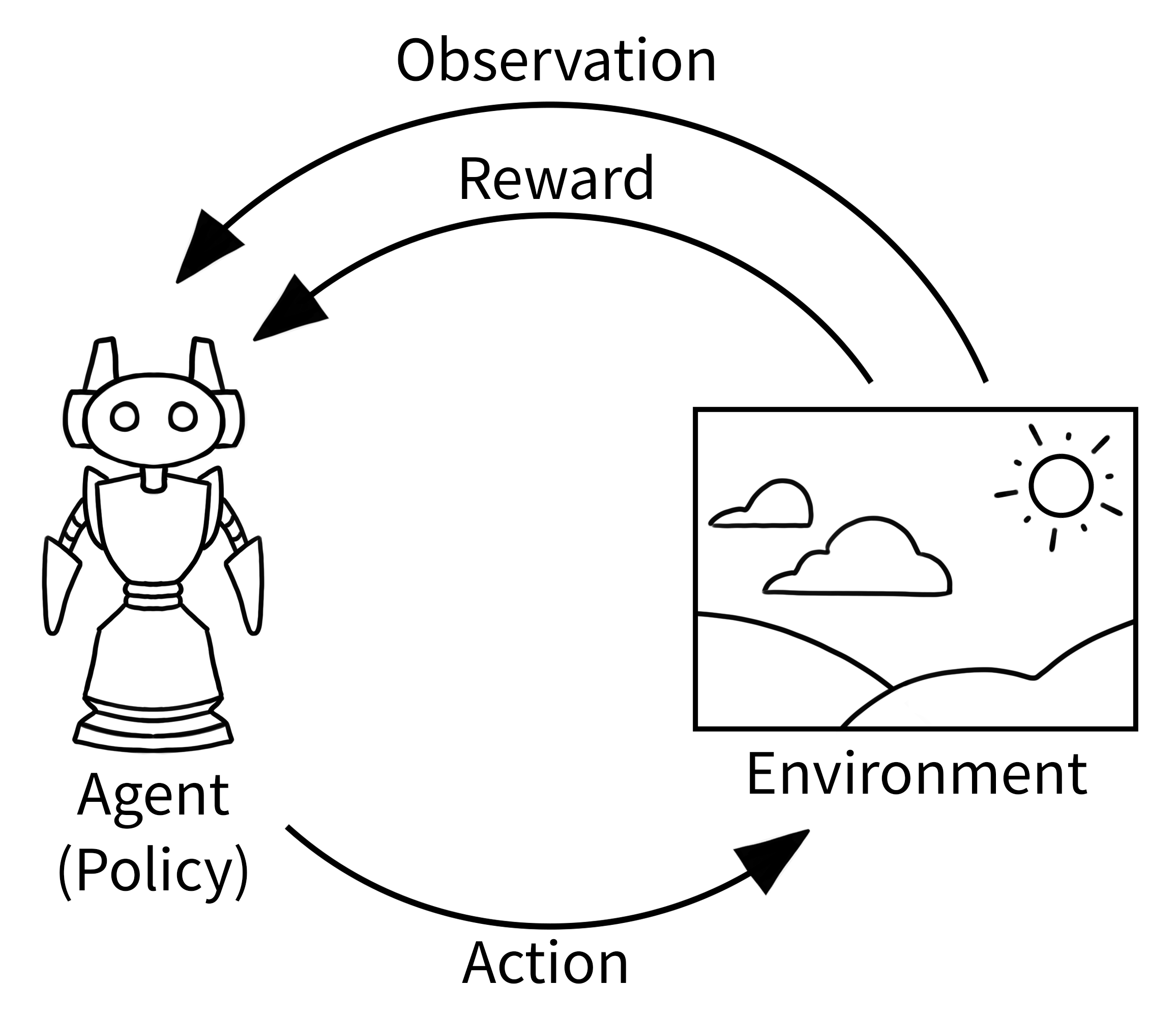
What you see around you is your environment. If you extend that analogy into the world of LMs, then anything that a LM is able to interact with becomes its environment. Put another way, the environment defines the loop of "state -> action -> reward". These are three key components of an environment:
- State: The current observations about the world for the LM. (e.g., question, tools, etc.)
- Action: The action that the LM takes, either in the form of reasoning, direct response, or a tool call. (e.g., "Call
get_weatherto get the current weather") - Feedback: The result of the action taken by the LM, sent as feedback to the LM. (e.g., "✔️
get_weather()tool called, reward = 1.0")
An extremely simple example of this is the math-python environment, which defines:
- A Python REPL as a tool
- Reward functions that judge correctness using symbolic equivalence and number of errors as separate signals
Another example of an environment is the Wordle game, where the LM is tasked with solving a puzzle, and getting feedback on things such as correctness, number of steps taken, etc. It's easy to see how this conceptual model can be applied to multiple domains when scaled up:
computer-usebecomes an environment where the LM has access to a browser and receives feedback on tasks such as navigating to a webpagecodingbecomes an environment where the LM has access to a code editor, the terminal, and receives feedback on tasks such as solving issues, fixing bugs, etc.<something>becomes an environment where the LM has access to<thing 1>, <thing 2>, ...and receives feedback on areas such as<task 1>, <task 2>, ....
But how do we use these environments?
Hopefully, you're now sold on the idea of environments, but that's just the first half of the puzzle. The other challenge comes from the fact that these environments are not defined in a uniform way, which makes it difficult to replicate results, and thus, trust benchmarks.
A benchmark is created when a particular dataset (or a set of datasets) is used to evaluate the performance of a LM on a given environment. Even if the dataset doesn't change, the way it's processed, or the way the LM is invoked may not be the same.
The verifiers project is a great attempt at solving this problem. It aims to provide a standardized way of defining environments with LEGO-esque blocks: datasets, parsers, rubrics, and rollout. You can read more about the technical implementation here, but I will talk about my experience when porting two benchmarks to PrimeIntellect's Environment Hub.
Porting environments to the Hub
Late Friday night, I saw this tweet from @willccbb crowdsourcing efforts for agent dev work. I was already looking into RL, so this was the perfect opportunity to learn by doing. I ended up porting two benchmarks using the verifiers library to create environments: BrowseComp by OpenAI, and LisanBench by @scaling01
In both, the general design that I followed to work with the verifiers library was:
- Loading the dataset: Each environment defines its dataset differently, but the general idea is the same:
Create a Hugging Face dataset with "question" and "answer" columns, where each row defines an example.
-
Creating a parser: The parser is responsible for actually reading the LM response and extracting points of interest. This is extremely useful if your domain has a custom format that you would like to work on top of. The library also offers a few helpers such as
vf.ThinkParserandvf.XMLParserfor common use cases. -
Creating reward functions for defining rubrics: The rubric is a set of functions that take in the prompt, completion, state, and returns a number defining the value of a specific signal. This reward can either be deterministic (e.g., check
2 + 2 = 4), or stochastic (e.g., using LLM-as-judge to measure reward). Each reward can be weighted and grouped to create different signals.
For example, a simple reward function would be:
def exact_match(prompt, completion, answer, state):
"""Reward exact matches."""
response = parser.parse(completion)
return 1.0 if response.strip() == answer.strip() else 0.0
- Creating a rollout strategy: The rollout strategy defines how the LM interacts with the environment. Broadly, this can be thought of as a "single turn", where the LM is given a question and an answer is returned, or "multi turn", where the LM is given a question and is allowed to interact with the environment multiple times until it decides to terminate (similar to ReAct).
The library is quite simple to understand and the documentation is a great resource to get started.
Running an evaluation
Something new that I tried out was actually running an open-source model on a GPU, and then running an evaluation using the Environment Hub. I've dabbled with running models directly before, but those were in the context of diffusion models (see here).
It was quite easy to get a hosted instance at PrimeIntellect. I went with a single L40S to keep things simple, and then logged into the instance using the ssh command. Once in, the steps to set up an inference server were:
- Install
uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
- Clone the
prime-rlrepo:
git clone https://github.com/primeintellect/prime-rl.git
- Install the dependencies:
cd prime-rl
uv sync
To actually run the server, you will need to define a infer.toml (similar to the configs/**/infer.toml files in the repo) file somewhere with your configuration. To follow along, this is the one I used:
[model]
model = "Qwen/Qwen3-0.6B"
With that defined, you can run:
uv run inference @ <path-to-your-infer.toml>
This will start the server through vLLM (takes a while to start up), and serve a FastAPI server at http://localhost:8000/v1. From here, you basically have your own OpenAI-compatible API server that you point your applications to.
Installing the environment
Once you have the server running, you can install the example environment by running:
cd /prime-rl/environments
prime env pull adi-kmt/nyt-connections
To run the evaluation, you can use the vf-eval command:
cd adi-kmt-nyt-connections-latest
uv run vf-eval nyt-connections -m "Qwen/Qwen3-0.6B" -b "http://localhost:8000/v1" -k "_API_KEY" -n 10 -r 2 -c 4 -a '{"num_eval_samples": 10}' -s
With that, the library will run the evaluation with the defined settings, and you should see the results in the terminal. To view it in a more interactive way, you can use uv run vf-tui from the same directory to open a dashboard.
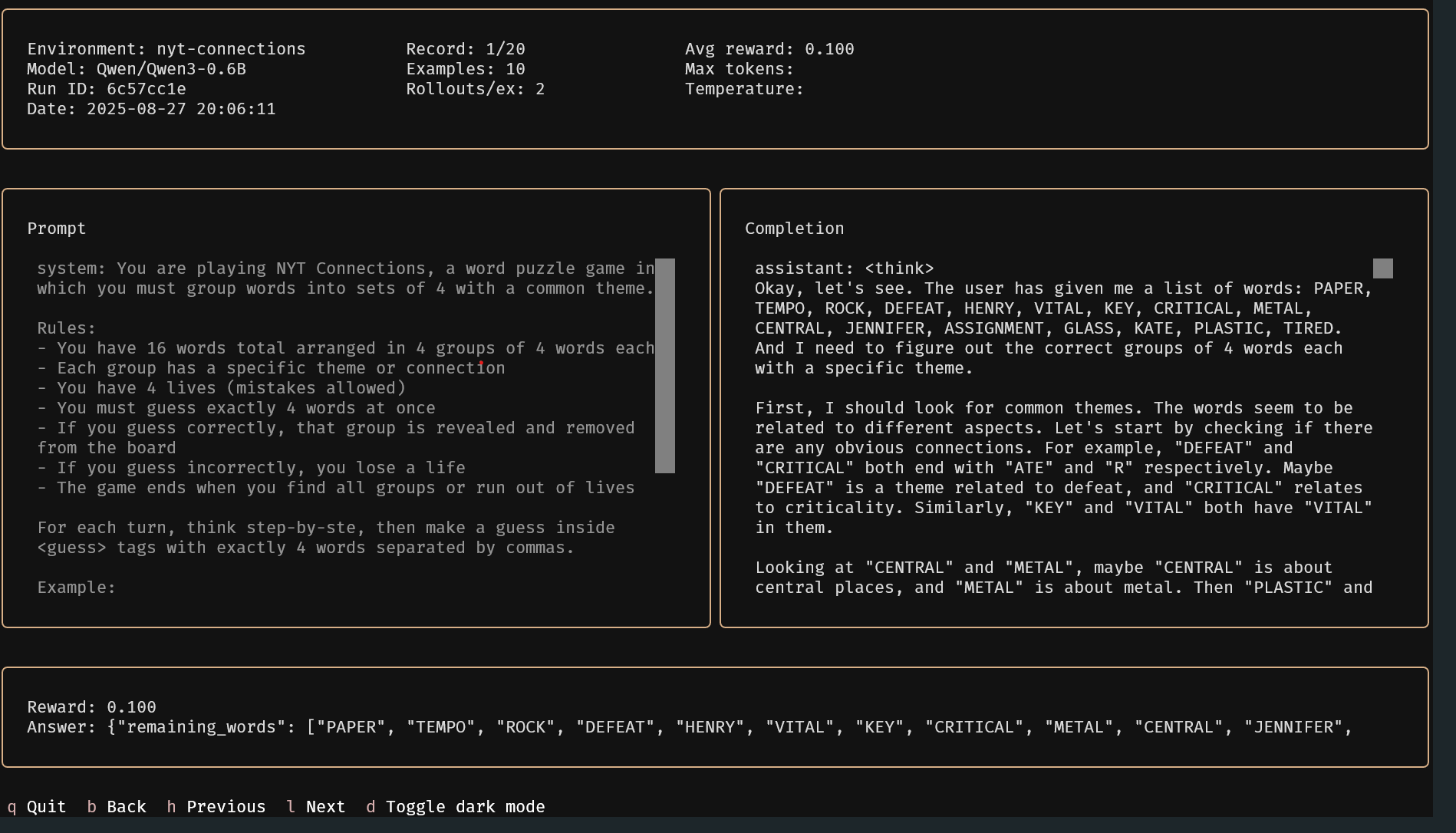
As we can see above, the Qwen/Qwen3-0.6B model gets an average reward of 0.1 across the 10 examples, with each example running twice to account for variance.
Next steps
It was a great learning experience, and I'm grateful to Will and the Prime Intellect team for the opportunity to work on this and learn from it. I ended up shipping a couple of contributions to the verifiers repository as well for some quality-of-life improvements.
I'm going to continue exploring this space - my next objective is to actually train a small model on an environment and follow that process to learn more.
This is not a sponsored post. I am genuinely impressed with the work that Prime Intellect is doing, and want to push the boundaries to help reach open-source AGI.
Thanks for reading! If you would like to chat more custom RL environments, or just discuss generally about the whole space, hit me up on X/Twitter or LinkedIn.